In my previous post I talked about something called String Hashing which is basically a function that generates a hash string based on a binary string.
In today post we will talk about on really useful algorithm called HMAC (Hash-based Message Authentication Code) which provides a way to generate a secure hash based on a string. Same as the hash function we wrote recently.
Why do we use something like HMAC?
On the internet we normally send messages between parties. The issue here is that, not being able to read the message doesn’t mean that you can’t interview with the meaning of the message. Anybody could interfiere with this communication and change the message between the parties.
This is when encrypted messages come into play and HMAC attempt protect this communication within the cipher and basically garantes that the messages hasn’t been changed.
In cryptography, a cipher (or cypher) is an algorithm for performing encryption or decryption.
One bit at the time
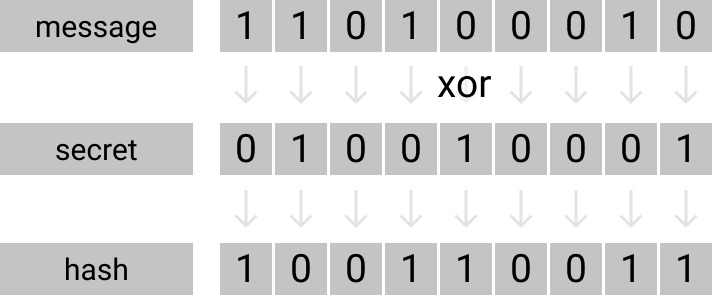
Let’s try to understand how a normal hashing function work.
What we normally do is to XOR every bit of our message against out secret binary which will produce our final hash.
"my message" XOR "myrandomstring" = "myhash"
The main issue is that a middle man could just reverse this process and see the actual message in the cipher.
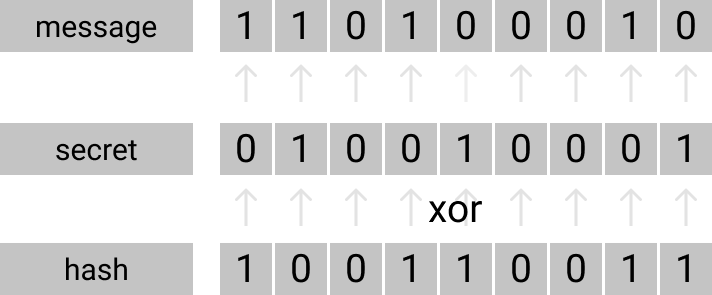
HMAC allows us to encrypt and sign the message with a Secret key and then only decrypt it using the same key. So, our middle man cannot see the message while is being sent.
This is an easy example of what would happen if a middle man tries to tweak our hash
If the hash is valid, then the payload can be verified
String hashing is a technique for converting a string into a hash number. Why do we need that? Sometimes we need to compare large strings, but instead comparing the string we can compare the generated hash.
Imagine that you had to compare the next two string:
const A = "imagine that this is a string of 200 characters"
const B = "imagine that this is a string of 200 characterz"
Both strings have 200 characters. A brute force way would be to compare each character and see if they match. Something like:
const A = "imagine that this is a string of 200 characters"
const B = "imagine that this is a string of 200 characterz"
function equal(A, B) {
let i;
for(i = 0; i < A.length; i++){
if (A[i] !== B[i]) {
return false;
}
}
return true;
}
console.log(equal(A,B));
This isn’t optimal with big strings because of it’s O(min(A, B)) performance.
Of course we could make this O(n) by adding a condition that compares A size and B size. Something like:
function equal(A, B) {
if (A.lenght !== B.length) return false;
let i;
for(i = 0; i < A.length; i++){
if (A[i] !== B[i]) {
return false;
}
}
return true;
}
As I said, worst scenario would be O(n), but imagine that we had to compare a really large string.
String Hashing is a technique where we can convert our strings into an Integer which will act as a hash number. Therefore, we will be comparing two hashes hash(A) == hash(B) this will be considered O(1). That’s the best option we can have for comparing two strings.
String Hash Formula
Where p and m are prime numbers, and s[0], s[1], s[2]... are values for each character, in this case the char code.
p: It is a prime number roughly equal to number of different characters used. For example if we are going to calculate the hash for a word that includes only lower case characters of the English alphabet, 31 would be a good number. However, if we will include upper case characters, then 53 is an appropriate option.
m: The bigger this number is, the less chance we have to collide two random strings. this variable should be also a prime number. 10 ^9 + 9 is a common choice.
Lets use this data:
p = 31
m = 1e9 + 9
word = 'apple'
We want to know what’s the hash code for the word apple, so if we add our data to our formula, we would have something like this:
then
then we get the char code:
"a" = 97
"p" = 112
"p" = 112
"l" = 108
"e" = 101
and replace this in the formula:
then we reduce the formula:
Finally
So our final hash for the word apple would be 96604250
I’ll leave you the implementation on JavaScript
function hash(word) {
var p = 31;
var m = 1e9 + 9;
var hash_value = 0;
for(var i = 0; i < word.length; i++) {
var letter = word[i];
var charCode = letter.charCodeAt();
hash_value = hash_value + (charCode * Math.pow(p, i))
}
return hash_value % m;
}
console.log(hash("apple"));
ping me on my twitter @jorgechavz and send me your own implementation.
This is probably one of the most useful search algorithms you will use when solving computer science problems. I’ll try to explain this search method the best I can.
In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array.
Wikipedia
When searching in an array with Binary Search we need to make sure that the array is sorted, you will see why in a moment.
Linear search
Let’s create a really simple scenario, let’s pretend I give you this array:
Then I ask you to find if this array has the number 90. A linear search approach would loop through the array and check if the current item is indeed our target value, in this case the number 90. JavaScript code would look alike this:
Worst case scenario would be O(N) because if the element you want to find is the last one, you will loop on the entire array.
This isn’t optimal for a sorted array, binary search time complexity is O(Log N) which is normally a better option when we threat with large data sets.
Binary search approach
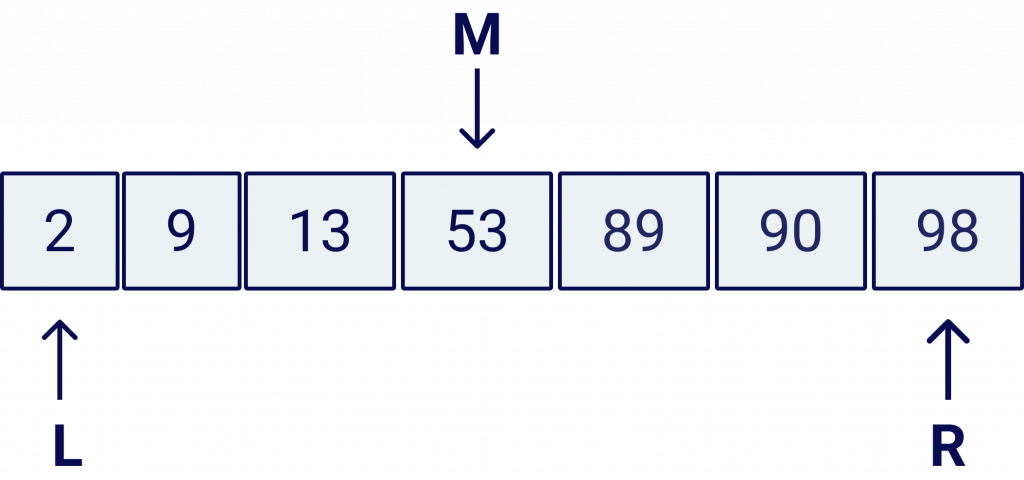
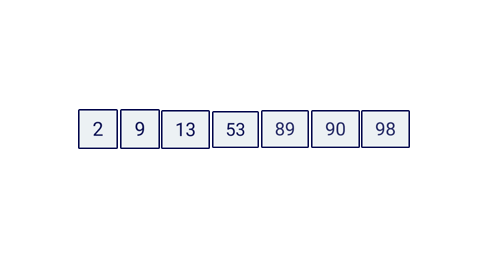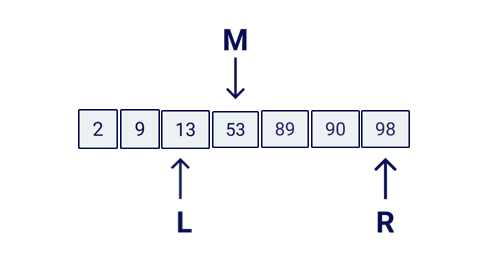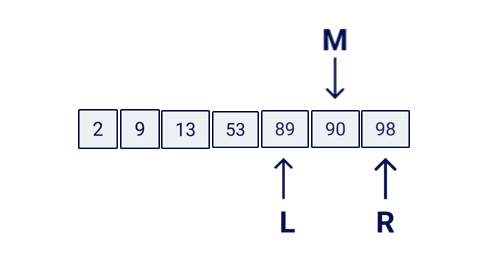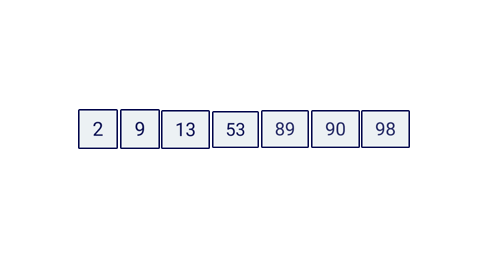
For this algorithm we will need 3 pointers:
L: Left pointer
R: Right pointer
M: Middle pointer
Graphically this would look like this:
The algorithm goes like this:
Start L pointing to the first element of the array.
Start R pointing to the last item.
Start a while loop until L <= R.
Everything inside this loop will be repeated each time:
Start M pointing to the greatest middle value (floor) between L and R.
Check if the element in M position is the one you a looking for. If so, return the value.
At this point we need to discard one half of the array, basically chop it from the M position. We can decide which side by either converting L = M + 1 or R = M - 1. This will depends on if the element is being pointed by M is greater or lower than our target value.
If L <= R the loop will end and it will mean that our target value is not in the array.
Code:
const items = [2, 9, 13, 53, 89, 90, 98];
const searchBinary = (elements, search) => {
let L = 0;
const n = elements.length;
let R = n - 1;
while(L <= R) {
let M = Math.floor((L + R) / 2);
if (elements[M] === search) return M;
if (elements[M] < search) {
L = M + 1;
} else {
R = M - 1;
}
}
return -1;
}
console.log(searchBinary(items, 89));
Here is a little animation of how this algorithm would work:
Special cases
What if there are duplicated values in our array? The previous approach will still works. However, it will only respond to the question “Is there any90 in the array?” but what if you need the leftmost value, or the rightmost value. See the next example so you can visualize the issue with our first approach:
Leftmost
See how in the next animation, M starts in target value, but with this approach we will need to wait until L and R crosses, so it doesn’t matter if M is already in one of the target values..
Let’s tweak a little bit our current code so we can find the leftmost element.
const items = [2, 9, 13, 53, 89, 90, 90, 98, 100, 102];
const binarySearchLeftMost = (elements, search) => {
let L = 0;
const n = elements.length;
let R = n;
while (L < R) {
M = Math.floor((L + R) / 2);
if (elements[M] < search) {
L = M + 1;
} else {
R = M;
}
}
return L;
}
console.log(binarySearchLeftMost(items, 90));
Rightmost
Very similar to leftmost, we need need to chop all the right duplicated values right away, then start moving L closer and closer to R.
const items = [2, 9, 13, 53, 89, 90, 90, 98, 100, 102];
const binarySearchRightMost = (elements, search) => {
let L = 0;
const n = elements.length;
let R = n;
while (L < R) {
M = Math.floor((L + R) / 2);
if (elements[M] > search) {
R = M;
} else {
L = M + 1;
}
}
return L;
}
console.log(binarySearchRightMost(items, 90));
Conclusion
Binary search is a great algorithm for searching through a sorted array, we can either verify if an element is within the array, find the first occurrence or the last occurrence.
I hope you enjoyed and learned from this post, if you have any question let ping me on my twitter @jorgechavz
Sometimes, solving a problem isn’t the main issue. Problems can have many different solutions and we as developers need to fine the best solution. But what makes a solution better against others? The answer can vary. However, when we write an algorithm we will try to find the solution that solves the problem faster (time), and the one that uses less resources (memory).
Time complexity
Time complexity represents the time or memory that an algorithm takes in order to complete the solution. The less time an algorithm takes, the happier our end users will be. So, knowing how to write more efficient algorithms is crucial for having better performance in our software.
How do we go about analyzing which solutions are most efficient?
Big O Notation
We can represent time complexity with math, here is when Big O Notation come to play. This notation is just a way of analyzing how long an algorithm with a given number of inputs (n) will take to complete its task.
Here are some simple time complexities with its Big O Notation, feel free to look in Wikipedia for more in-depth definitions:
O(1)Constant time: It doesn’t matter the n number of elements in our data. It will just take a single step for complete the task. A clear example is the access of an item into an array
const fruits = ["apple", "pineapple", "orange"];
// The time for getting the last item will be
// the same than getting the first item.
console.log(fruits[0]);
console.log(fruits[2]);
O(s)Linear runtime: Everything will depends on the value of s. The bigger s is, the more time it will take to resolve the algorithm. A for loop could be an example. The loop will take s number of iterations to get out of the loop.
for(let i; i < s; i++) {
console.log(i);
}
Representation of a linear time and a constant time.
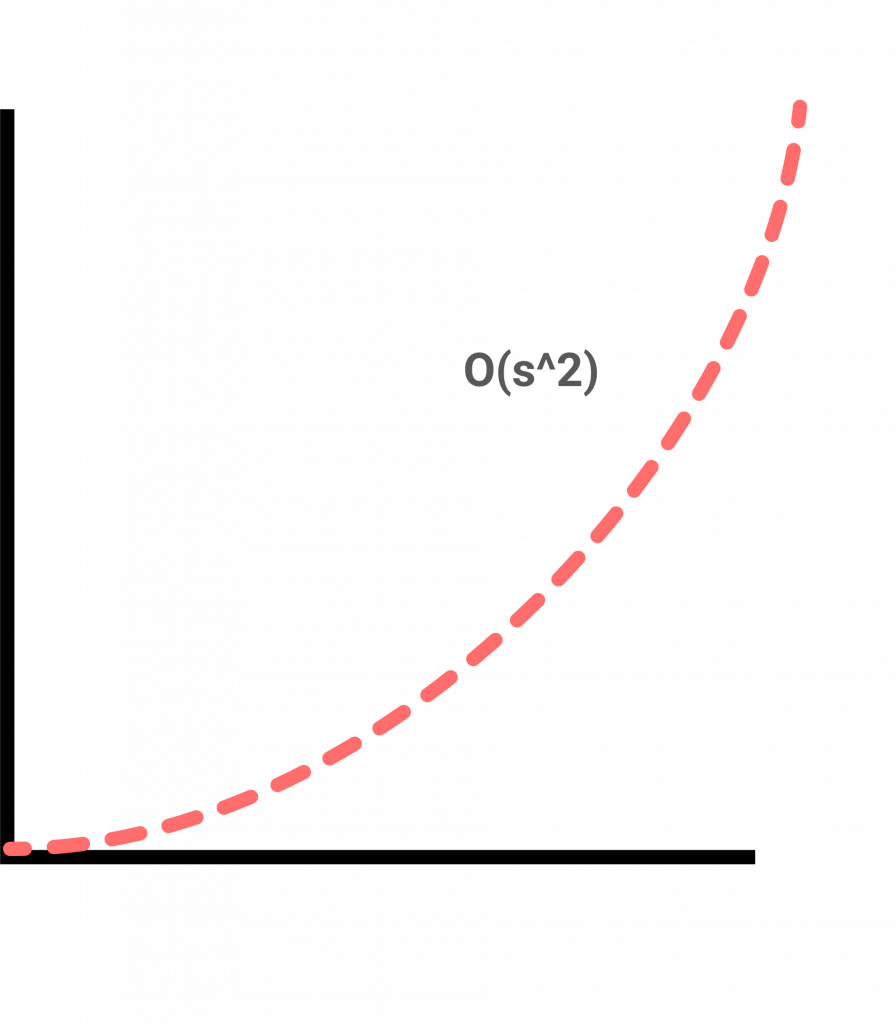
O(s2)Quadratic time: It is really common on algorithms that involve nested iterations. Giving n size, it will take square n to complete the task.
O(log n)Logarithmic time: Given an input of size n, the number of steps it takes to accomplish the task are decreased by some factor with each step. For example, a binary search could be logarithmic since with every step we reduce the possible solutions in half, so the more iterations the closest we are for completing the task.
Conclusion
Time complexity and Big O Notation will help us to understand an a more visible way if an algorithm is faster or not. Different data structures have different running time. So, understanding this topics will allow us to use data structures that can fit well for a better performance.
We won’t cover all time complexities. However, I hope this short post gives you an idea of what time complexity is and how to represent those running times with math (Big O Notation).